(寫在獲獎後)
逐家好,Ta̍k-ke hó。
原本是抱持著單純參賽與記錄工作經驗的心情來撰寫文章的,沒想到非常幸運地獲得評審的青睞,能獲得這次的冠軍。
誠如原文所述,筆者自己做為一名半路出家,而且工作經驗才剛滿一年多的菜鳥工程師,自認在技術這一塊還是有非常多可以進步的地方,是需要再向各位前輩學習的。
但也正因如此,文章中許多困難的問題,都仰賴了團隊中其他優秀的工程師前輩的指點,以及之前在轉職中有遇到的神隊友和老師的協助,當然也還有團隊中產品經理的溝通與合作。如果沒有他們,這個系列文章是不可能完成的,因此希望可以在此將這份榮耀和喜稅分享給他們,也同時勉勵自己能夠更努力,成為能夠獨當一面的工程師。
因為深知技術領域實在有太多可以學習的地方,可以的話想多認識一些前輩,歡迎隨時在 LinkedIn 上與我建立連結,也希望未來有機會再向各位學習。
感謝!
------------------------------以下原文------------------------------
哈囉,感謝點進來看看這個系列文章,請稱呼我為Sean即可以了。
進行這次的挑戰,除了受到景仰的工程師邀請之外,同時也想要記錄身為SRE菜鳥,這一年來的工作心得。
更重要的是,與一些開發工程師聊天的時候,常發現他們對於SRE這個職位其實有很大的興趣,卻不知道應該從什麼地方下手。
可以的話,也想要藉由這篇文章,來讓開發為主的工程師能夠一窺SRE平常的工作內容,在互相交流的同時,也可以更加完善這個職位的整體文化。
因此,這一系列文章的主要受眾,會是針對在軟體工程領域有開發經驗,但對維運本身沒有什麼經驗,同時也想要稍微一探究竟的人。
這30天的文章主要會分成以下幾個主題(也可能會隨著書寫的狀況而修改):
筆者在接下來文章裡面提到的所有內容,都會是實際在目前工作岡位上遇到的事情。雖然可能會與其它公司的實際業務有所不同(比如我們是全雲端的服務,但有些公司可能有地端伺服器),但也會盡量用比較泛用的方式來描述。
另外,為了避免一些不必要的誤會,接下來的介紹都會針對服務或功能本身,分享的同時也會隱藏或適度修改一些數據或經驗,以保護公司內部的資訊。事實上,許多過去經驗裡有提到的資訊,早就與現在的狀況完全不同了。因此如有故事雷同純屬巧合,也請不要做出不必要的猜想或憶測喔。
最後,作為一位半路出家的工程師,實際在業界工作的資歷大約也只有一年左右,與許多資深的前輩相比應該還有非常多不足的地方,若有任何更好的見解,都歡迎提出來討論和指教。感謝!
那事不宜遲,我們先來稍微介紹第一天的主題吧。
所謂的基本監控系統,是指說不管在哪一個專案上面都會廣泛的套用類似的監控方式。實際上,在敝公司裡面有好幾個大型專案,雖然各自會有因為業務不同而開發出來的監控系統,但在那之前,一定會先有一套基本的監控系統。
請見下圖:
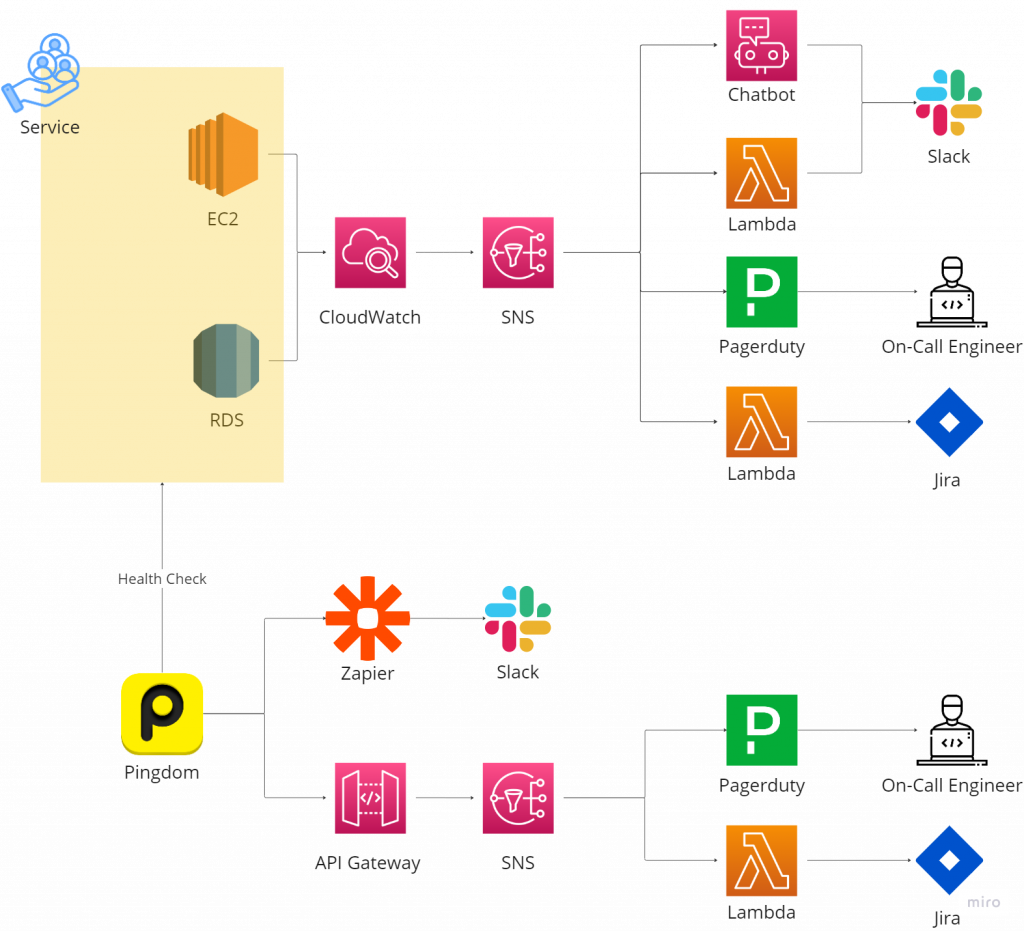
如上圖,在左上角Service的地方是我們的主要服務所在的位置(全部在AWS雲端)。整套監控系統主要分成2個部分,分別是是內部的監控和外部的監控。
在內部的監控部分,我們透過AWS原生的CloudWatch來監控各類伺服器的使用狀況,比如API伺服器(EC2)或資料庫伺服器(RDS)的CPU使用量,在異常(比如CPU大於90%)的時候,透過訊息派發服務(SNS)來將告警訊息傳給指定的對象。
在外部的監控部分,我們透過Pingdom這個服務來定期存取我們想要監控的網站或API,在無法存取的時候(相當於是網站或API已經無法使用的時候),同樣透過各種方式來將告警訊息傳給指定的對象。
換個說法來講,如果收到的是內部的監控告警,通常不一定會影響到服務本身的可用性(availability),但如果收到來自外部的監控告警(Pingdom DOWN),則代表服務本身已經無法使用。因此後者通常會是比較嚴重的狀況。
指定的對象包含3個,首先會透過PagerDuty來叫醒執班工程師,同時把告警訊息透過Lamda或Chatbot來傳到Slack,最後再把該告警的詳細內容透過另一支Lambda來記錄Jira上以供後續內部討論。
值班工程師必須要在5分鐘內有明確的動作,否則就有可能驚動另一個專門與客戶接洽的團隊。這邊補充一點背景,因為我們是B2B的產品,所以我們主要面對的不是end-user,而是另一個公司。因此我們也同時建立了一群專門與他們直接接洽的團隊。
除了針對系統的監控,我們也會監控各種服務的升級和維護通知,如下圖:

在某些AWS上面的服務(比如RDS)收到升級的要求時,我們透過串接AWS Health API(AHA)與Slack,並要求值班工程師定期檢查Slack的方式來獲得相關資訊。值班工程師會把相關資訊傳達給產品經理後,請產品經理協助與客戶協調升級和維護的時間。
值得一提的是,雖然這些升級看起來微不足到,但因為數量繁雜,所以也不太好處理。有時候也會遇到一些大規模的升級要求或因為服務的End of Live(EOL)而導致的搬遷(Migration)要求。這些筆者也會在之後的文章中重點說明。


